Where Am I?
Overview and East/West Traffic
SNAT
* Floating IPs
In The Good Old Days…
Legacy routers provide floating IPs connectivity by performing 1:1 NAT between the VM’s fixed IP and its floating IP inside the router namespace. Additionally, the L3 agent throws out a gratuitous ARP when it configures the floating IP on the router’s external device. This is done to advertise to the external network that the floating IP is reachable via the router’s external device’s MAC address. Floating IPs are configured as /32 prefixes on the router’s external device and so the router answers any ARP requests for these addresses. Legacy routers are of course scheduled only on a select subgroup of nodes known as network nodes.
Things Are About to Get Weird
In the DVR world, however, things are very different. This is going to get very complicated very fast so let’s understand how and why we got there. We could have kept things the way they are and configured floating IPs on the router’s ‘qg’ device. Or could we? Let’s consider that for a moment:
- MAC addresses! Network engineers go to great lengths to minimize broadcast domains because networking devices have fairly modest upper bounds on their MAC tables. Most external networks use flat or VLAN networking: It is possible to subdivide them by using multiple external networks, or multiple subnets on a single external network, but let’s consider a single external network for the purpose of this discussion. With legacy routers you would ‘consume’ a MAC address on the external network per router. If we kept the existing model but distributed the routers, we would consume a MAC address for every (node, router) pair. This would quickly explode the size of the broadcast domain. Not good!
- IP addresses! Legacy routers configure a routable address on their external devices. It’s not wasted by any means because it is used for SNAT traffic. With DVR, as we noticed in the previous blog post, we do the same. Do we actually need a dedicated router IP per compute node then? No, not really. Not for FIP NAT purposes. You might want one for troubleshooting purposes, but it’s not needed for NAT. Instead, it was chosen to allocate a dedicated IP address for every (node, external network) pair.
Where We Ended Up
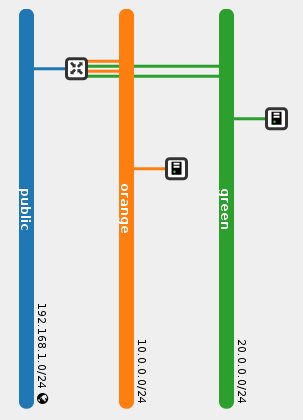
Let’s jump ahead and see how everything is wired up (On compute nodes):
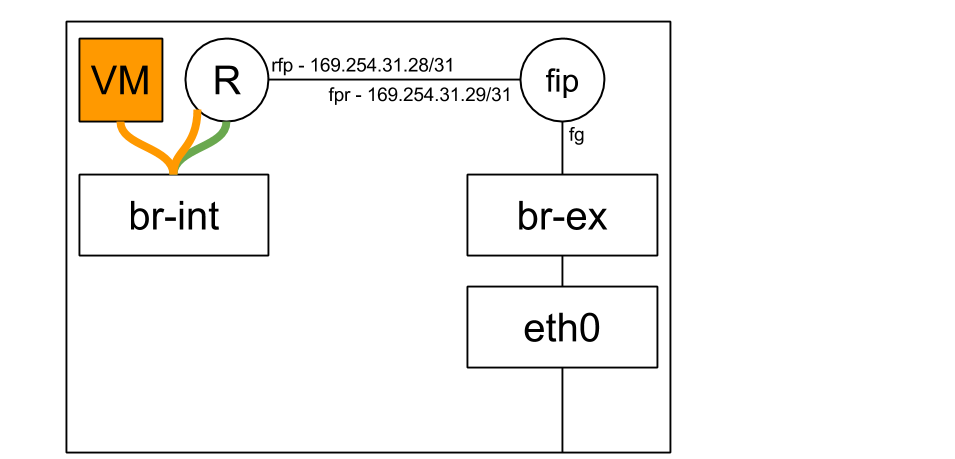
When a floating IP is attached to a VM, the L3 agent creates a FIP namespace (If one does not already exist) for the external network that the FIP belongs to:
[stack@vpn-6-21 devstack (master=)]$ ip netns
fip-cef4f7b4-c344-4904-a847-a9960f58fb20
qrouter-ef25020f-012c-41d6-a36e-f2f09cb8ea62
As we can see the fip namespace name is determined by the ID of the external network it represents:
[stack@vpn-6-21 devstack (master=)]$ neutron net-show public
...
| id | cef4f7b4-c344-4904-a847-a9960f58fb20 |
...
Every router on the compute node is hooked up to the FIP namespace via a veth pair (Quick reminder: A veth pair is a type of Linux networking device that is represented by a pair of devices. Whatever goes in on one end leaves via the other end. Each end of the pair may be configured with its own IP address. Veth pairs are often used to interconnect namespaces as each end of the pair may be put in a namespace of your choosing).
The ‘rfp’ or ‘router to FIP’ end of the pair resides in the router namespace:
[stack@vpn-6-21 devstack (master=)]$ sudo ip netns exec qrouter-ef25020f-012c-41d6-a36e-f2f09cb8ea62 ip address
...
3: rfp-ef25020f-0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 16:91:f5:0b:34:50 brd ff:ff:ff:ff:ff:ff
inet 169.254.31.28/31 scope global rfp-ef25020f-0
inet 192.168.1.3/32 brd 192.168.1.3 scope global rfp-ef25020f-0
...
52: qr-369f59a5-2c: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:33:6d:d7 brd ff:ff:ff:ff:ff:ff
inet 20.0.0.1/24 brd 20.0.0.255 scope global qr-369f59a5-2c
...
53: qr-c2e43983-5c: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:df:74:6c brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 brd 10.0.0.255 scope global qr-c2e43983-5c
...
While the ‘fpr’ or ‘FIP to router’ end of the pair resides in the FIP namespace, along with the ‘fg’ / external device:
[stack@vpn-6-21 devstack (master=)]$ sudo ip netns exec fip-cef4f7b4-c344-4904-a847-a9960f58fb20 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
...
3: fpr-ef25020f-0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 3e:d3:e7:34:f6:f3 brd ff:ff:ff:ff:ff:ff
inet 169.254.31.29/31 scope global fpr-ef25020f-0
...
59: fg-b2b77eed-1b: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether fa:16:3e:cc:98:c8 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.23/24 brd 192.168.1.255 scope global fg-b2b77eed-1b
...
As you’ve surely noticed, the rfp and fpr are configured with link local IP addresses. Every time a router is configured on a compute node and hooked up to the FIP namespace in case a floating IP was configured on said router, a pair of free IP addresses is allocated out of a large pool of 169.254.x.y. These allocations are then persisted locally on the node’s disk in case the agent or the node decide to do the unthinkable and reboot.
Before we track a packet as it leaves a VM, let’s observe the routing rules in the router namespace:
[stack@vpn-6-21 devstack (master=)]$ sudo ip netns exec qrouter-ef25020f-012c-41d6-a36e-f2f09cb8ea62 ip rule
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
32768: from 10.0.0.4 lookup 16
167772161: from 10.0.0.1/24 lookup 167772161
335544321: from 20.0.0.1/24 lookup 335544321
Huzzah, a new source routing rule! This time it’s a specific rule with our VM’s fixed IP address. You’ll notice that it has a lower (Better) priority than the generic rules that follow. We’ll expand on this in a moment.
Tracking a Packet
In the previous blog post we talked about classifying east/west and SNAT traffic and forwarding appropriately. Today we are joined by a third traffic class: Floating IP traffic. SNAT and floating IP traffic is differentiated by the ip rules shown above. Whenever a floating IP is configured by a L3 agent it adds a rule specific to that IP: It adds the fixed IP of the VM to the rules table, and a new routing table (In this example ’16’):
[stack@vpn-6-21 devstack (master=)]$ sudo ip netns exec qrouter-ef25020f-012c-41d6-a36e-f2f09cb8ea62 ip route show table 16
default via 169.254.31.29 dev rfp-ef25020f-0
If VM 10.0.0.4 (With floating IP 192.168.1.3) sends traffic destined to the outside world, it arrives in the local qrouter namespace and the ip rules are consulted just like in the SNAT example in the previous blog post. The main routing table doesn’t have a default route, and the ‘32768: from 10.0.0.4 lookup 16′ rule is matched. The routing table known as ’16’ has a single entry, a default route with 169.254.31.29 as the next hop. The qrouter iptables NAT rules apply and the source IP is replaced with 192.168.1.3. The message is then forwarded with 169.254.31.29’s MAC address via the rfp device, landing squarely in the FIP namespace using its ‘fpr’ device. The FIP namespace routing table has a default route, and the packet leaves through the ‘fg’ device.
The opposing direction is similar, but there’s a catch. How does the outside world know where is the VM’s floating IP address: 192.168.1.3? In fact, how does the fip namespace know where it is? It has an IP address in that subnet, but the address itself is a hop away in the qrouter namespace. To solve both problems, proxy ARP is enabled on the ‘fg’ device in the FIP namespace. This means that the FIP namespace will answer ARP requests for IP addresses that reside on its own interfaces, as well as addresses it knows how to route to. To this end, every floating IP is configured with a route from the FIP namespace back to the router’s namespace as we can see below:
[stack@vpn-6-21 devstack (master=)]$ sudo ip netns exec fip-cef4f7b4-c344-4904-a847-a9960f58fb20 ip route
default via 192.168.1.1 dev fg-b2b77eed-1b
169.254.31.28/31 dev fpr-ef25020f-0 proto kernel scope link src 169.254.31.29
192.168.1.0/24 dev fg-b2b77eed-1b proto kernel scope link src 192.168.1.23
192.168.1.3 via 169.254.31.28 dev fpr-ef25020f-0
When the outside world wants to contact the VM’s floating IP, the FIP namespace will reply that 192.168.1.3 is available via the fg’s device MAC address (An awful lie, but a useful one… Such is the life of a proxy). The traffic will be forwarded to the machine, in through a NIC connected to br-ex and in to the FIP’s namespace ‘fg’ device. The FIP namespace will use its route to 192.168.1.3 and route it out its fpr veth device. The message will be received by the qrouter namespace: 192.168.1.3 is configured on its rfp device, its iptables rules will replace the packet’s destination IP with the VM’s fixed IP of 10.0.0.4 and off to the VM the message goes. To confuse this business even more, gratuitous ARPs are sent out just like with legacy routers. Here however, the floating IP is not actually configured on the ‘fg’ device. This is why it is configured temporarily right before the GARP is sent and removed right afterwards.
A Summary of Sorts