
I’ve observed a persistent theme across valuable and successful CI systems, and that is actionable results.
A CI system for a project as complicated as OpenStack requires a staggering amount of energy to maintain and improve. Often times the responsible parties are focused on keeping it green and are buried under a mountain of continuous failures, legit or otherwise. So much so that they don’t have time to focus on the following questions:
- How do you determine that a job failed?
- How are the results presented to the relevant developers?
- Can developers do anything about a failure?
To bring it to concrete terms let’s take a look at how Rally is used in upstream jobs. This is not a criticism of the Rally project itself, which I’m a big fan of, but rather how it’s used upstream. It uses the standard upstream CI infrastructure, which is a miracle of engineering when it comes to correctness tests. The infrastructure spins up VMs from a node pool comprised of many clouds. It then uses devstack-gate and devstack to install OpenStack and runs several Rally scenarios. When the result of a CI run is True or False, the variance of hardware and congestion levels is irrelevant. However, when you’re trying to measure performance, variance matters. You can try setting a maximum, and any result over the maximum is declared as a failure, however with a variance sufficiently large setting up SLAs is an exercise in futility.
Let’s look at a recent Linux Bridge change [1] that cannot impact Rally results (The Rally job is setup to run against Open vSwitch). Consecutive runs would ideally show the same results. However, looking at the results of patchsets 10, 11, 13 and 14, we can see that the total length of the job runs between 60 and 83 minutes. The full duration of the create_and_list_ports flow runs from 1517 seconds to 1887 seconds. The average for a single create_and_list_ports execution runs between 4.58s and 5.29s. What am I supposed to do with the results of the next run? What can I learn from it? I’d argue: Nothing. The results of the job are not actionable. The result is that the job has been non-voting ever since its introduction and worse yet, none of the engineers I work with look at its results.
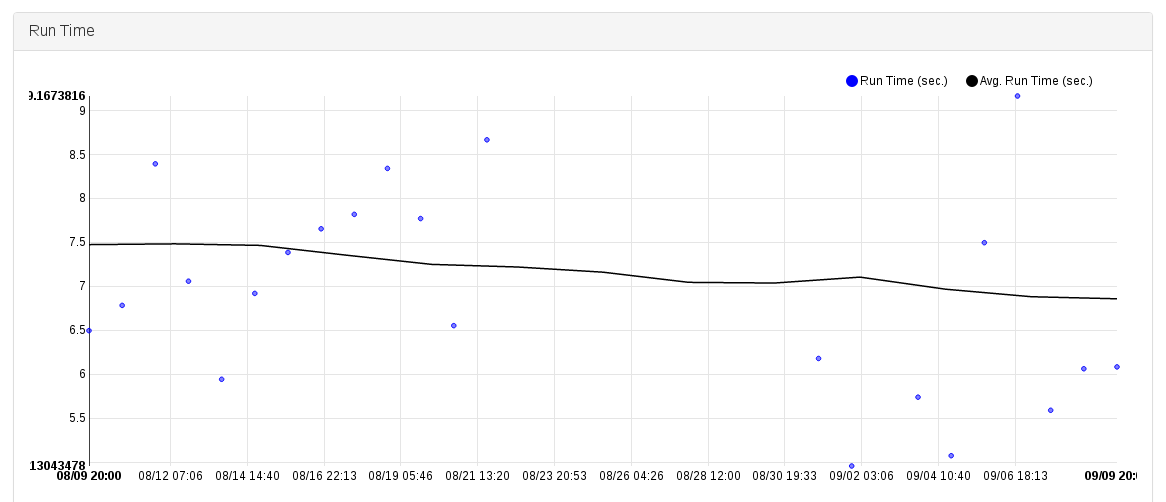
The next step would be to give up on the idea of gating or blocking performance regressions and instead detect them after the fact. We can do that by persisting historical results, graphing them and spotting trends. It’s clear that with a variance this large, the results would not be actionable either. To demonstrate this, let’s turn to the fantastic openstack-health project. Looking at the Neutron API test with the longest average run time [2] we can see that at the time of writing, the test ran 249 times in the past month so we get a great sample size. However, the run time graph looks like a Jackson Pollock painting, with a min of just under 5s and a max of just over 9s. Looking at the graph it’s clear we can’t clean up the data via statistical Jiu Jitsu either. When consistency matters, I don’t think you can get around a dedicated bare metal setup.
The Gerrit interface does a great job of presenting CI results, and a failing voting job forces developers to look at its results. However, I don’t know many engineers who look at CI results as a form of amusement. Post-merge and periodic CI runs in to these issues – They burn your favorite form of fossil fuels and drain the life force of the fine folks who maintain it but the results are often not presented in a consumable manner. Running the tests reliably is as important as making sure the intended audience is aware of the results. One solution could be to make sure the relevant developers subscribe to a mailing list, triggering a mail on failures filtered after distracting infrastructure issues. Periodic CI can only be valuable if it’s actionable and developers are held accountable and demonstrate a persistent urgency to failures.
[1] https://review.openstack.org/#/c/346377/
[2] http://status.openstack.org/openstack-health/#/test/neutron.tests.tempest.api.test_auto_allocated_topology.TestAutoAllocatedTopology.test_get_allocated_net_topology_as_tenant?resolutionKey=day&duration=P1M
