Prefix
In the GRE tunnels post I’ve explained how overlay networks are used for connectivity and tenant isolation. In the l2pop post, or layer 2 population, I explained how OVS forwarding tables are pre-populated when instances are brought up. Today I’ll talk about another form of table pre-population – The ARP table. This feature has been introduced with this patch by Edouard Thuleau, merged during the Juno development cycle.
ARP – Why do we need it?
In any environment, be it the physical data-center, your home, or a virtualization cloud, machines need to know the MAC, or physical network address, of the next hop. For example, let there be two machines connected directly via a switch:
The first machine has an IP address of 10.0.0.1, and a MAC address of 0000:DEAD:BEEF,
while the second machine has an IP address of 10.0.0.2, and a MAC address of 2222:FACE:B00C.
I merrily log into the first machine and hit ‘ping 10.0.0.2’, my computer places 10.0.0.2 in the destination IP field of the IP packet, then attempts to place a destination MAC address in the Ethernet header, and politely bonks itself on its digital forehead. Messages must be forwarded out of a computer’s NIC with the destination MAC address of the next hop (In this case 10.0.0,2, as they’re directly connected). This is so switches know where to forward the frame to, for example.
Well, at this point, the first computer has never talked to the second one, so of course it doesn’t know its MAC address. How do you discover something that you don’t know? You ask! In this case, you shout. 10.0.0.1 will flood, or broadcast, an ARP request saying: What is the MAC address of 10.0.0.2? This message will be received by the entire broadcast domain. 10.0.0.2 will receive this message (Amongst others) and happily reply, in unicast: I am 10.0.0.2 and my MAC address is 2222:FACE:B00C. The first computer will receive the ARP reply and will then be able to fill in the destination MAC address field, and finally send the ping.
Will this entire process be repeated every time the two computers wish to talk to each other? No. Sane devices keep a local cache of ARP responses. In Linux you may view the current cache with the ‘arp’ command.
A slightly more complex case would be two computers separated by a layer 3 hop, or a router. In this case the two computers are in different subnets, for example 10.0.0.0/8 and 20.0.0.0/8. When the first computer pings the second one, the OS will notice that the destination is in a different subnet, and thus forward the message to the default gateway. In this case the ARP request will be sent for the MAC address of the pre-configured default gateway IP address. A device only cares about the MAC address of the next hop, not of the final destination.
The absurdity of L2pop without an ARP responder
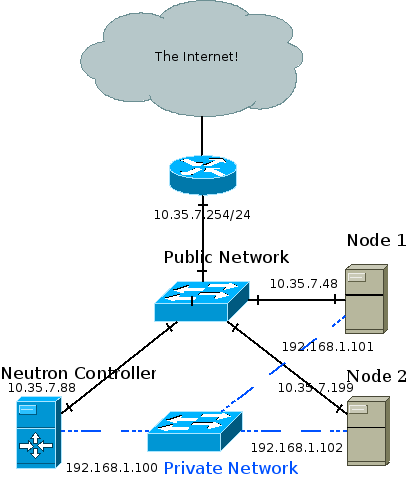
Let there be VM 1 hosted on compute node A, and VM 2 hosted on compute node B.
With l2pop disabled, when VM 1 sends an initial message to VM 2, compute node A won’t know the MAC address of VM 2 and will be forced to flood the message out all tunnels, to all compute nodes. When the reply is received, node A would learn the MAC address of VM 2 along with the remote node and tunnel ID. This way, future floods are prevented. L2pop prevents even the initial flood by pre-populating the tables, as the Neutron service is aware of VM MAC addresses, scheduling, and tunnel IDs. More information may be found in the dedicated L2pop post.
So, we optimized one broadcast, but what about ARPs? Compute node A is aware of the MAC address (And whereabouts) of VM 2, but VM 1 isn’t. Thus, when sending an initial message from VM 1 to 2, an ARP request will be sent out. Compute node A knows the MAC address of VM 2 but chooses to put a blindfold over its eyes and send a broadcast anyway. Well, with the ARP responder feature this is no longer case.
The OVS ARP responder – How does it work?
A new table is inserted into the br-tun OVS bridge, to be used as an ARP table. Whenever a message is received by br-tun from a local VM, it is classified into unicast, broadcast/multicast and now ARP requests. ARP requests go into the ARP table, where pre-learned MAC addresses (Via l2pop, more in a minute) reside. Rows in this table are then matched against the (ARP protocol, network, IP of the requested VM) tuple. The resulting action is to construct an ARP reply that will contain the IP and MAC addresses of the remote VM, and will be sent back from the port it came in on to the VM making the original request. If a match is not found (For example, if the VM is trying to access a physical device not managed by Neutron, thus was never learned via L2pop), the ARP table contains a final default flow, to resubmit the message to the broadcast/multicast table, and the message will be treated like any old broadcast.
The table is filled whenever new L2pop address changes come in. For example, when VM 3 is hosted on compute C, both compute nodes A and B get a message that a VM 3 with IP address ‘x’ and MAC address ‘y’ is now on host C, in network ‘z’. Thus, compute nodes A and B can now fill their respective ARP tables with VM 3’s IP and MAC addresses.
The interesting code is currently at:
For help on reading OVS tables, and an explanation of OVS flows and how they’re comprised of match and action parts, please see a previous post.
Blow by blow:
Here’s the action part:
actions = (‘move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],’ – Place the source MAC address of the request (The requesting VM) as the new reply’s destination MAC address
‘mod_dl_src:%(mac)s,’ – Put the requested MAC address of the remote VM as this message’s source MAC address
‘load:0x2->NXM_OF_ARP_OP[],’ – Put an 0x2 code as the type of the ARP message. 0x2 is an ARP response.
‘move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],’ – Place the ARP request’s source hardware address (MAC) as this new message’s ARP target / destination hardware address
‘move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],’ – Place the ARP request’s source protocol / IP address as the new message’s ARP destination IP address
‘load:%(mac)#x->NXM_NX_ARP_SHA[],’ – Place the requested VM’s MAC address as the source MAC address of the ARP reply
‘load:%(ip)#x->NXM_OF_ARP_SPA[],’ – Place the requested VM’s IP address as the source IP address of the ARP reply
‘in_port’ % {‘mac’: mac, ‘ip’: ip}) – Forward the message back to the port it came in on
self.tun_br.add_flow(table=constants.ARP_RESPONDER, – Add this new flow to the ARP_RESPONDER table
priority=1, – With a priority of 1 (Another, default flow with the lower priority of 0 is added elsewhere in the code)
proto=‘arp’, – Match only on ARP messages
dl_vlan=lvid, – Match only if the destination VLAN (The message has been locally VLAN tagged by now) matches the VLAN ID / network of the remote VM
nw_dst=‘%s‘ % ip, – Match on the IP address of the remote VM in question
actions=actions)
Example:
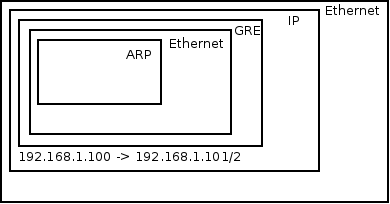
An ARP request comes in.
In the Ethernet frame, the source MAC address is A, the destination MAC address is FFFF:FFFF:FFFF.
In the ARP header, the source IP address is 10.0.0.1, the destination IP is 10.0.0.2, the source MAC is A, and the destination MAC is FFFF:FFFF:FFFF.
Please make sure that entire part makes sense before moving on.
Assuming L2pop has already learned about VM B, the hypervisor’s ARP table will already contain an ARP entry for VM B, with IP 10.0.0.2 and MAC B.
Will this message be matched? Sure, the proto is ‘arp’, they’re in the same network so dl_vlan will be correct, and nw_dst (This part is slightly confusing) will correctly match on the destination IP address of the ARP header, seeing as ARP replaces IP in the third layer during ARP messages.
What will be the action? Well, we’d expect an ARP reply. Remember that ARP replies reverse the source and destination so that the source MAC and IP inside the ARP header are the MAC and IP addresses of the machine we asked about originally, and the destination MAC address in the ARP header is the MAC address of the machine originating the ARP request. Similarly we’d expect that the source MAC of the Ethernet frame would be the MAC of the VM we’re querying about, and the destination MAC of the Ethernet frame would be the MAC of the VM originating the ARP request. If you carefully observe the explanation of the action part above, you would see that this is indeed the case.
Thus, the source MAC of the Ethernet frame would be B, the destination MAC A. In the ARP header, the source IP 10.0.0.2 and source MAC B, while the destination IP 10.0.0.1 and destination MAC A. This ARP reply will be forwarded back through the port which it came in on and will be received by VM A. VM A will unpack the ARP reply and find the MAC address which it queried about in the source MAC address of the ARP header.
Turning it on
Assuming ML2 + OVS >= 2.1:
- Turn on GRE or VXLAN tenant networks as you normally would
- Enable l2pop
- On the Neutron API node, in the conf file you pass to the Neutron service (plugin.ini / ml2_conf.ini):
[ml2] mechanism_drivers = openvswitch,l2population
- On each compute node, in the conf file you pass to the OVS agent (plugin.ini / ml2_conf.ini):
[agent] l2_population = True
- Enable the ARP responder: On each compute node, in the conf file you pass to the OVS agent (plugin.ini / ml2_conf.ini):
[agent] arp_responder = True
To summarize, you must use VXLAN or GRE tenant networks, you must enable l2pop, and finally you need to enable the arp_responder flag in the [agent] section in the conf file you pass to the OVS agent on each compute node.
Thanks
Props to Edouard Thuleau for taking the initiative and doing the hard work, and for the rest of the Neutron team in the lengthy review process! It took us nearly 8 months but we finally got it merged, in fantastic shape.