
L3 Agent Low Availability
Today, you can utilize multiple network nodes to achieve load sharing, but not high availability or redundancy. Assuming three network nodes, creation of new routers will be scheduled and distributed amongst those three nodes. However, if a node drops, all routers on that node will cease to exist as well as any traffic normally forwarded by those routers. Neutron, in the Icehouse release, doesn’t support any built-in solution.
A Detour to the DHCP Agent
DHCP agents are a different beast altogether – The DHCP protocol allows for the co-existence of multiple DHCP servers all serving the same pool, at the same time.
By changing:
neutron.conf: dhcp_agents_per_network = X
You will change the DHCP scheduler to schedule X DHCP agents per network. So, for a deployment with 3 network nodes, and setting dhcp_agents_per_network to 2, every Neutron network will be served by 2 DHCP agents out of 3. How does this work?
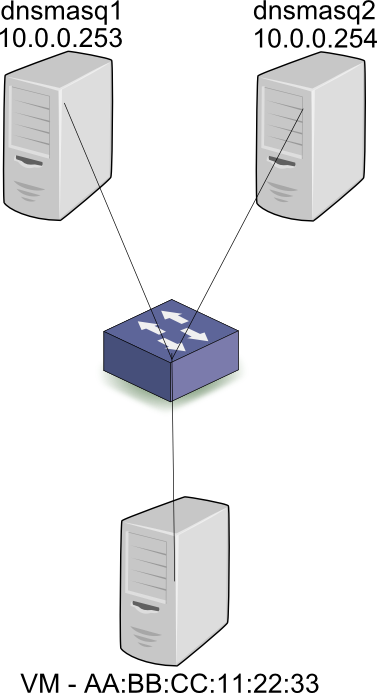
First, let’s take a look at the story from a baremetal perspective, outside of the cloud world. When the workstation is connected to a subnet in the 10.0.0.0/24 subnet, it broadcasts a DHCP discover. Both DHCP servers dnsmasq1 and dnsmasq2 (Or other implementations of a DHCP server) receive the broadcast and respond with an offer for 10.0.0.2. Assuming that the first server’s response was received by the workstation first, it will then broadcast a request for 10.0.0.2, and specify the IP address of dnsmasq1 – 10.0.0.253. Both servers receive the broadcast, but only dnsmasq1 responds with an ACK. Since all DHCP communication is via broadcasts, server 2 also receives the ACK, and can mark 10.0.0.2 as taken by AA:BB:CC:11:22:33, so as to not offer it to other workstations. To summarize, all communication between clients and servers is done via broadcasts and thus the state (What IPs are used at any given time, and by who) can be distributed across the servers correctly.
In the Neutron case, the assignment from MAC to IP is configured on each dnsmasq server beforehand, when the Neutron port is created. Thus, both dnsmasq leases file will hold the AA:BB:CC:11:22:33 to 10.0.0.2 mapping before the DHCP request is even broadcast. As you can see, DHCP HA is supported at the protocol level.
Back to the Lowly Available L3 Agent
L3 agents don’t (Currently) have any of these fancy tricks that DHCP offers, and yet the people demand high availability. So what are the people doing?
- Pacemaker / Corosync – Use external clustering technologies to specify a standby network node for an active one. The standby node will essentially sit there looking pretty, and when a failure is detected with the active node, the L3 agent will be started on the standby node. The two nodes are configured with the same hostname so that when the secondary agent goes live and synchronizes with the server, it identifies itself with the same ID and thus manages the same routers.
- Another type of solution writes a script that runs as a cron job. This would be a Python SDK script that would use the API to get a list of dead agents, get all the routers on that agent, and reschedule them to other agents.
- In the Juno time frame, look for this patch https://review.openstack.org/#/c/110893/ by Kevin Benton to bake rescheduling into Neutron itself.
Rescheduling Routers Takes a Long, Long Time
All solutions listed suffer from a substantial failover time, if only for the simple fact that configuring a non-trivial amount of routers on the new node(s) takes quite a while. Thousands of routers take hours to finish the rescheduling and configuration process. The people demand fast failover!
Distributed Virtual Router
DVR has multiple documents explaining how it works:
- http://specs.openstack.org/openstack/neutron-specs/specs/juno/neutron-ovs-dvr.html
- https://docs.google.com/document/d/1jCmraZGirmXq5V1MtRqhjdZCbUfiwBhRkUjDXGt5QUQ/
- https://docs.google.com/document/d/1depasJSnGZPOnRLxEC_PYsVLcGVFXZLqP52RFTe21BE/
The gist is that it moves routing to the compute nodes, rendering the L3 agent on the network nodes pointless. Or does it?
- DVR handles only floating IPs, leaving SNAT to the L3 agents on the network nodes
- Doesn’t work with VLANs, only works with tunnels and L2pop enabled
- Requires external connectivity on every compute node
- Generally speaking, is a significant departure from Havana or Icehouse Neutron based clouds, while L3 HA is a simpler change to make for your deployment
Ideally you would use DVR together with L3 HA. Floating IP traffic would be routed directly by your compute nodes, while SNAT traffic would go through the HA L3 agents on the network nodes.
Layer 3 High Availability
The Juno targeted L3 HA solution uses the popular Linux keepalived tool, which uses VRRP internally. First, then, let’s discuss VRRP.
What is VRRP, how does it work in the physical world?
Virtual Router Redundancy Protocol is a first hop redundancy protocol – It aims to provide high availability of the network’s default gateway, or the next hop of a route. What problem does it solve? In a network topology with two routers providing internet connectivity, you could assign half of the network’s default gateway to the first router’s IP address, and the other half to the second router.

This would provide load sharing, but what happens if one router loses connectivity? Herein comes the idea of a virtual IP address, or a floating address, which will be configured as the network’s default gateway. During a failover, the standby routers won’t receive VRRP hello messages from the master and will thus perform an election process, with the winning router acting as the active gateway, and the others remain as standby. The active router configures the virtual IP address (Or VIP for short), on its internal, LAN facing interface, and responds to ARP requests with a virtual MAC address. The network computers already have entries in their ARP caches (For the VIP + virtual MAC address) and have no reason to resend an ARP request. Following the election process, the virtuous standby router becomes the new active instance, and sends a gratuitous ARP request – Proclaiming to the network that the VIP + MAC pair now belong to it. The switches comprising the network move the virtual MAC address from the old port to the new.

By doing so, traffic to the default gateway will reach the correct (New) active router. Note that this approach does not accomplish load sharing, in the sense that all traffic is forwarded through the active router. (Note that in the Neutron use case, load sharing is not accomplished at the individual router level, but at the node level, assuming a non-trivial amount of routers). How does one accomplish load sharing at the router resolution? VRRP groups: The VRRP header includes a Virtual Router Identifier, or VRID. Half of the network hosts will configure the first VIP, and the other half the second. In the case of a failure, the VIP previously found on the failing router will transfer to another one.

The observant reader will have identified a problem – What if the active router loses connectivity to the internet? Will it remain as the active router, unable to route packets? VRRP adds the capability to monitor the external link and relinquish its role as the active router in case of a failure.
Note: As far as IP addressing goes, it’s possible to operate in two modes:
- Each router gets an IP address, regardless of its VRRP state. The master router is configured with the VIP as an additional or secondary address.
- Only the VIP is configured. IE: The master router will hold the VIP while the slaves will have no IPs configured whatsoever.
VRRP – The Dry Facts
- Encapsulated directly in the IP protocol
- Active instance uses multicast address 224.0.0.18, MAC 01-00-5E-00-00-12 when sending hello messages to its standby routers
- The virtual MAC address is of the form: 00-00-5E-00-01-{VRID}, thus only 256 different VRIDs (0 to 255) can exist in a single broadcast domain
- The election process uses a user configurable priority, from 1 to 255, the higher the better
- Preemptive elections, like in other network protocols, means that if a standby is configured with a higher priority, or comes back after losing its connectivity (And previously acting as the active instance) it will resume its role as the active router
- Non-preemptive elections mean that when an active router loses its connectivity and comes back up, it will remain in a standby role
- The hello internal is configurable (Say: Every T seconds), and standby routers perform an election process if they haven’t received a hello message from the master after 3T seconds
Back to Neutron-land
L3 HA starts a keepalived instance in every router namespace. The different router instances talk to one another via a dedicated HA network, one per tenant. This network is created under the blank tenant to hide it from the CLI and GUI. The HA network is a Neutron tenant network, same as every other network, and uses the default segmentation technology. HA routers have an ‘HA’ device in their namespace: When a HA router is created, it is scheduled to a number of network nodes, along with a port per network node, belonging to the tenant’s HA network. keepalived traffic is forwarded through the HA device (As specified in the keepalived.conf file used by the keepalived instance in the router namespace). Here’s the output of ‘ip address’ in the router namespace:
[stack@vpn-6-88 ~]$ sudo ip netns exec qrouter-b30064f9-414e-4c98-ab42-646197c74020 ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
...
2794: ha-45249562-ec: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 12:34:56:78:2b:5d brd ff:ff:ff:ff:ff:ff
inet 169.254.0.2/24 brd 169.254.0.255 scope global ha-54b92d86-4f
valid_lft forever preferred_lft forever
inet6 fe80::1034:56ff:fe78:2b5d/64 scope link
valid_lft forever preferred_lft forever
2795: qr-dc9d93c6-e2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global qr-0d51eced-0f
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever
2796: qg-843de7e6-8f: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 19.4.4.4/24 scope global qg-75688938-8d
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever
That is the output for the master instance. The same router on another node would have no IP address on the ha, qr, or qg devices. It would have no floating IPs or routing entries. These are persisted as configuration values in keepalived.conf, and when keepalived detects the master instance failing, these addresses (Or: VIPs) are configured by keepalived on the appropriate devices. Here’s an example of keepalived.conf, for the same router shown above:
vrrp_sync_group VG_1 {
group {
VR_1
}
notify_backup "/path/to/notify_backup.sh"
notify_master "/path/to/notify_master.sh"
notify_fault "/path/to/notify_fault.sh"
}
vrrp_instance VR_1 {
state BACKUP
interface ha-45249562-ec
virtual_router_id 1
priority 50
nopreempt
advert_int 2
track_interface {
ha-45249562-ec
}
virtual_ipaddress {
19.4.4.4/24 dev qg-843de7e6-8f
}
virtual_ipaddress_excluded {
10.0.0.1/24 dev qr-dc9d93c6-e2
}
virtual_routes {
0.0.0.0/0 via 19.4.4.1 dev qg-843de7e6-8f
}
}
What are those notify scripts? These are scripts that keepalived executes upon transition to master, backup, or fault. Here’s the contents of the master script:
#!/usr/bin/env bash neutron-ns-metadata-proxy --pid_file=/tmp/tmpp_6Lcx/tmpllLzNs/external/pids/b30064f9-414e-4c98-ab42-646197c74020/pid --metadata_proxy_socket=/tmp/tmpp_6Lcx/tmpllLzNs/metadata_proxy --router_id=b30064f9-414e-4c98-ab42-646197c74020 --state_path=/opt/openstack/neutron --metadata_port=9697 --debug --verbose echo -n master > /tmp/tmpp_6Lcx/tmpllLzNs/ha_confs/b30064f9-414e-4c98-ab42-646197c74020/state
The master script simply opens up the metadata proxy, and writes the state to a state file, which can be later read by the L3 agent. The backup and fault scripts kill the proxy and write their respective states to the aforementioned state file. This means that the metadata proxy will be live only on the master router instance.
* Aren’t We Forgetting the Metadata Agent?
Simply enable the agent on every network node and you’re good to go.
Future Work & Limitations
- TCP connection tracking – With the current implementation, TCP sessions are broken on failover. The idea is to use conntrackd in order to replicate the session states across HA routers, so that when the failover finishes, TCP sessions will continue where they left off.
- Where is the master instance hosted? As it is now it is impossible for the admin to know which network node is hosting the master instance of a HA router. The plan is for the agents to report this information and for the server to expose it via the API.
- Evacuating an agent – Ideally bringing down a node for maintenance should cause all of the HA router instances on said node to relinquish their master states, speeding up the failover process.
- Notifying L2pop of VIP movements – Consider the IP/MAC of the router on a tenant network. Only the master instance will actually have the IP configured, but the same Neutron port and same MAC will show up on all participating network nodes. This might have adverse effects on the L2pop mechanism driver, as it expects a MAC address in a single location in the network. The plan to solve this deficiency is to send an RPC message from the agent whenever it detects a VRRP state change, so that when a router becomes the master, the controller is notified, which can then update the L2pop state.
- FW, VPN and LB as a service integration. Both DVR and L3 HA have issues integrating with the advanced services, and a more serious look will be taken during the Kilo cycle.
- One HA network per tenant. This implies a limit of 255 HA routers per tenant, as each router takes up a VRID, and the VRRP protocol allows 255 distinct VRID values in a single broadcast domain.
Usage & Configuration
neutron.conf: l3_ha = True max_l3_agents_per_router = 2 min_l3_agents_per_router = 2
- l3_ha = True means that all router creations will default to HA (And not legacy) routers. This is turned off by default.
- You can set the max to a number between min and the number of network nodes in your deployment. If you deploy 4 net nodes but set max to 2, only two l3 agents will be used per HA router (One master, one slave).
- min is used as a sanity check: If you have two network nodes and one goes out momentarily, any new routers created during that time period will fail as you need at least <min> L3 agents up when creating a HA router.
l3_ha controls the default, while the CLI allows an admin (And only admins) to override that setting on a per router basis:
neutron router-create --ha=<True | False> router1
References
- Blueprint
- Spec
- How to test
- Code
- Dedicated wiki page
- Section in Neutron L3 sub team wiki (Including overview of patch dependencies and future work)

I’ve got a question for you that is similar in scope. Currently in OpenStack, we use a feature that was a patch in Essex, and made it into mainline Folsom. This is where we define a gateway in the dnsmasq config on each node, using the label/tag of the network. In doing so, we use a hardware firewall for connectivity (the gateway). We haven’t (yet) found a reliable method to do this with Neutron. How would we accomplish this?
If you’re interested in a hardware gateway, you can use an admin created network to assign the appropriate VLAN tag, and simply configure that subnet’s gateway to match your physical gateway.
Awesome!
Nit:
“have no IP address on the ha, hr, or qg devices. ”
hr here should be qr.
🙂
Thanks, fixed 🙂
Not all DHCP is broadcast.
When the DHCP client knows the address of a DHCP server, in either
INIT or REBOOTING state, the client may use that address in the
DHCPDISCOVER or DHCPREQUEST rather than the IP broadcast address.
Especially Linux sometimes opts to UNICAST, but Windows can do it too, I think. Search for DhcpConnEnableBcastFlagToggle
Y.
Pingback: OpenStack Community Weekly Newsletter (Aug 15 – 22) » The OpenStack Blog
Pingback: What’s Coming in OpenStack Networking for Juno Release | Red Hat Stack
Nice article!
In the latest version of keepalived, it seems that it has used unicast to realize vrrp
Great!
I am testing the neutron L3 HA(using keepalived). One question is that how could it failover if ha device is still active but qg device or l3 agent is down?
Thanks!
Currently the only way to failover administratively is to shut down the HA device. Failing over when the external device is down has an open bug: https://bugs.launchpad.net/neutron/+bug/1365461. There’s a few bugs to get to before we tackle that one, but I’m hoping to fix that for Kilo. If you want to failover if the L3 agent is down: You’d have to monitor the agent via something like Pacemaker and set it up to bring down the HA device if it detects that the agent is down.
Pingback: Juno Advanced Routing Compatibility | Assaf Muller
Pingback: Distributed Virtual Routing – SNAT | Assaf Muller
Pingback: Adam Young: Networking Acronyms | Fedora Colombia
VRID segments tenant, but the password/md5 feature allows you to recycle the same VRID over and again as the hashes will not match and hence allow duplicate VRID co-existance (as long the secrets don’t match).